City of Seattle Open Data Risk Assessment
Shared for feedback by Future of Privacy Forum
The Future of Privacy Forum (FPF) requests feedback from the public on the proposed City of Seattle Open Data Risk Assessment . In 2016, the City of Seattle declared in its Open Data Policy that the city’s data would be “open by preference,” except when doing so may affect individual privacy. To ensure its Open Data program effectively protects individuals, Seattle committed to performing an annual risk assessment and tasked FPF with creating and deploying an initial privacy risk assessment methodology for open data.
This Draft Report provides tools and guidance to the City of Seattle and other municipalities navigating the complex policy, operational, technical, organizational, and ethical standards that support privacy-protective open data programs. In the spirit of openness and collaboration, FPF invites public comments from the Seattle community, privacy and open data experts, and all other interested individuals and stakeholders regarding this proposed framework and methodology for assessing the privacy risks of a municipal open data program.
Following this period of public comment, a Final Report will assess the City of Seattle as a model municipality and provide detailed recommendations to enable the Seattle Open Data program’s approach to identify and address key privacy, ethical and equity risks, in light of the city’s current policies and practices.
How to Comment:
All timely and responsive public comments will be considered and will be made available on a publicly accessible FPF or City of Seattle website after the final report is published. Because comments will be made public to the extent practical, they should not include any sensitive or confidential information. Comments are due October 2, 2017. Interested parties may provide feedback in any of the following ways:
- Publicly annotate, edit, or comment on the draft below.
- Email comments to comments@fpf.org.
- Write by mail to: Future of Privacy Forum ATTN: Open Data Privacy 1400 Eye Street NW Suite 450 Washington, D.C.
City of Seattle Open Data Risk Assessment
DRAFT REPORT
Executive Summary
The transparency goals of the open data movement serve important social, economic, and democratic functions in cities like Seattle. At the same time, some municipal datasets about the city and its citizens’ activities carry inherent risks to individual privacy when shared publicly. In 2016, the City of Seattle declared in its Open Data Policy that the city’s data would be “open by preference,” except when doing so may affect individual privacy. To ensure its Open Data program effectively protects individuals, Seattle committed to performing an annual risk assessment and tasked the Future of Privacy Forum (FPF) with creating and deploying an initial privacy risk assessment methodology for open data.
This Draft Report provides tools and guidance to the City of Seattle and other municipalities navigating the complex policy, operational, technical, organizational, and ethical standards that support privacy-protective open data programs. Although there is a growing body of research on open data privacy, open data managers and departmental data owners need to be able to employ a standardized methodology for assessing the privacy risks and benefits of particular datasets internally, without a bevy of expert statisticians, privacy lawyers, or philosophers. By following a flexible, risk-based assessment process, the City of Seattle – and other municipal open data programs – can maximize the utility and openness of civic data while minimizing privacy risks to individuals and community concerns about ethical challenges, fairness, and equity.
This Draft Report first describes inherent privacy risks in an open data landscape, with an emphasis on potential harms related to re-identification, data quality, and fairness. Accompanying this, the Draft Report includes a Model Open Data Benefit Risk Analysis (MODBRA). The model template evaluates the types of data contained in a proposed open dataset, the potential benefits – and concomitant risks – of releasing the dataset publicly, and strategies for effective de-identification and risk mitigation. This holistic assessment guides city officials to determine whether to release the dataset openly, in a limited access environment, or to withhold it from publication (absent countervailing public policy considerations). The Draft Report methodology builds on extensive work done in this field by experts at the National Institute of Standards and Technology, the University of Washington, the Berkman Klein Center for Internet & Society at Harvard University, and others, and adapts existing frameworks to the unique challenges faced by cities as local governments, technological system integrators, and consumer facing service providers.
Following a period of public comment and input on the Draft Report and proposed methodology, a Final Report will assess the City of Seattle as a model municipality, considering its open data program across six domains:
- Privacy leadership and management
- Benefit-risk assessments
- De-identification tools and strategies
- Data quality
- Data equity and fairness
- Transparency and public engagement
The Final Report will conclude by detailing concrete technical, operational, and organizational recommendations to enable the Seattle Open Data program’s approach to identify and address key privacy, ethical and equity risks, in light of the city’s current policies and practices.
The City of Seattle is one of the most innovative cities in the country, with an engaged and civic-minded citizenry, active urban leadership, and a technologically sophisticated business community. By continuing to complement its growing open data program with robust privacy protections and policies, the City of Seattle will be able to fulfill its goals, supporting civic innovation while protecting individual privacy in its Open Data program.
Acknowledgments: We extend our thanks to the experts from the City of Seattle, Seattle Community Technical Advisory Board, University of Washington, Berkman Klein Center for Internet & Society at Harvard University, members of the FPF Smart City Privacy Working Group, and others who provided their support and input in the development of this draft report. Special thanks to Jan Whittington, Meg Young, Ryan Calo, Mike Simon, Jesse Woo, and Peter Schmiedeskamp for their foundational scholarship and to Michael Mattmiller, Jim Loter, David Doyle, and the many Open Data Champs for their vision and dedication to making open data privacy a reality for the City of Seattle.
Background
In February 2016, City of Seattle Mayor Edward Murray issued an Executive Order calling for “all city data to be ‘open by preference’ – meaning city departments will make their data accessible to the public, after screening for privacy and security considerations.” The Executive Order “both sets the expectation that public data will be public and makes clear that [the city] has a responsibility to protect privacy.”
The City of Seattle Open Data Policy directs the City of Seattle to perform an annual risk assessment of both the Open Data Program and the content available on the Open Data Portal. For this, the City of Seattle contracted the Future of Privacy Forum to develop a methodology for conducting a risk assessment and to actively deploy the methodology. FPF will review a subset of high-risk agency datasets as well as a random sample of additional agency datasets, to evaluate privacy risks, including of re-identification, in case of release of individual datasets or multiple datasets.
From fall 2016 through summer 2017, FPF studied existing privacy and other risk assessment frameworks, created the Model Open Data Benefit Risk Analysis, and assessed the inherent privacy risks in the municipal open data landscape for the City of Seattle as a model municipality. In doing so, FPF built on open frameworks, such as the National Institute of Standards and Technology (NIST) Special Publication 800-series. In addition to a review of available research and policy guidance related to open data privacy risk, FPF conducted interviews with privacy, open data, and disclosure control experts from around the world.
FPF also visited on-site to conduct interviews with Seattle IT and Open Data leadership, departmental Open Data and Privacy Champions, and local community advisors. These interviews included teams from the Seattle IT, Seattle Police Department, Seattle Department of Transportation, Planning and Development, Parks and Recreation, Civil Rights, Immigrant Affairs, and the Seattle Public Library.
FPF presented an early draft of the identified privacy risks and assessment methodology to the Seattle Community Technology Advisory Board (CTAB) for review and input in February 2017. An additional 45-day period for public comment on the report will be offered from August through September 2017.
Open Data Privacy Risks
Open and accessible public data can benefit individuals, companies, communities, and government by unleashing new social, economic, and civic innovations and improving government accountability and transparency. Tremendous benefits in healthcare, education, housing, transportation, criminal justice, and public safety are already being realized as richer and more timely datasets are made available to the public. Open data can unite the power of city and private sector abilities to improve community health and lifestyles, including everything from bikeshare systems and commercial apps harnessing transit data to community advocates shining the light on ineffective or discriminatory practices through policing and criminal justice data.
In Seattle, for example, the Open Data program seeks to:
- “Improve public understanding of City operations and other information concerning their communities,
- Generate economic opportunity for individuals and companies that benefit from the knowledge created by Open Data,
- Empower City employees to be more effective, better coordinated internally, and able to identify opportunities to better serve the public, and
- Encourage the development of innovative technology solutions that improve quality of life.”
However, it can also pose substantial risks to the privacy of individuals whose information is collected and shared by the city. Inadequate privacy protections for open data can lead to significant financial, physical, reputational, organizational, and societal harms.
Cities must be vigilant and resourceful to deter and defend against these privacy risks, no matter how they arise. In this section, we describe the core privacy risks facing municipal open data programs: re-identification, biased or inaccurate data, and loss of public trust.
Re-identification
One of the principal and unavoidable risks of opening government datasets to the public is the possibility that the data might reveal private or sensitive information about a specific individual. In cases where open datasets are not adequately vetted, personally identifiable information (PII) may be published inadvertently. Even when a dataset has been scrubbed of names and other potentially identifying traits and rendered “de-identified,” there is a chance that someone (referred to in professional literature as an “adversary”)– whether an expert skilled in re-identifying individuals from seemingly “anonymous” information, or a commercial information reseller with access to millions of other data points, or an insider who knows other personal information – might be able to deduce that some of the data relates to a specific individual. Even information that appears on the surface to have no connection to a particular person can lead to re-identification in many circumstances. Because it is no longer always clear when data is “personally identifiable” and because data that was once non-identifiable may become identifying over time, municipalities should not rely on static lists of PII in determining if a particular dataset creates a risk of re-identification.
Re-identifying a person in this way not only exposes data about the individual that would otherwise not be available to the public, but could potentially carry embarrassing, damaging, or life-threatening implications. For example, in Dallas, the names of six people who complained of sexual assault were published online by the police department. While the Dallas Police Department does not intentionally publish such sensitive information, of course, its case classification scheme and overlapping information across datasets combined in such a way that the six injured parties could be singled out and identified when they should not have been. Other re-identification attacks may reveal an individual’s home address or place of work, exposing them to increased risk of burglary, property crime, or assault.
Recent advances in smart city technologies, re-identification science, data marketplaces, and big data analytics have enhanced re-identification risks, and thus increased the overall privacy risk in open datasets. As open data programs mature and shift from merely providing historic data and statistics to more granular, searchable, accessible, and comprehensive “microdata” about citizens and their activities, the risk of re-identification rises even further. Databases of calls to emergency services, civil complaints about building codes and restaurants, and even civil rights violations will potentially become available for anyone in the world to explore. The ease at which adversaries (including professional researchers, commercial organizations and data brokers, other government and law enforcement agencies, civic hackers, and individual members of the general public) can download, re-sort, and recombine these datasets carries an obvious risk for the leakage of sensitive data.
Even as open data programs take on the challenges of sophisticated re-identification adversaries combining multiple databases to reveal sensitive attributes about individuals, datasets that appear more bureaucratic or even mundane and therefore fail to raise the same privacy red flags – could ultimately leave individuals exposed. In 2017, for example, a parent who was examining expenditure files on the Chicago Public School’s website discovered that deep within the tens of thousands of rows of vendor payment data were some 4,500 files that identified students with Individualized Educational Programs – revealing in plain text the students’ names, identification numbers, the type of special education services that were being provided for them, how much those services cost, the names of therapists, and how often students met with the specialists.
One of the unavoidable challenges of open data is that once information has been published publicly, it likely can never be retracted. Unfortunately, data de-identification is a moving target – data that could not be linked to an individual when it was released, could become identifiable over time. For example, if sometime in the future another dataset is published that links one record to another or if a new technique becomes available to match information across multiple datasets, the difficulty of re-identifying an individual in the original open dataset may drop significantly. While it is difficult to predict when such future data may become available, cutting-edge research into more dynamic de-identification techniques is underway among disclosure control experts and at statistical agencies around the world.
As municipalities strive to lower the risk of open data re-identification, they are still at a disadvantage compared to many other public and private sector entities: no matter how sophisticated their safeguards may be for open datasets, public records laws may compel them to release the underlying data anyway. For example, the Washington state public records act compels the disclosure of even personally identifiable information as long as there is a legitimate concern to the public. Although Washington has one of the broadest public records acts in the U.S., if a city like Seattle determined that a dataset should not be proactively opened to the public because of it poses a risk to privacy, or that it should only be released with aggregate data, city officials may have no avenue for preventing the release of granular, potentially identifiable information. Furthermore, in many cases public records laws rely on outdated or inflexible definitions of PII, and fail to account for modern re-identification capabilities and the impact one dataset can have on the re-identifiability of others in the future. Because of the interplay of open data and public records requests, municipalities must be far-sighted in deciding what data they will collect in the first place.
Re-identification also harms municipalities: when data published on an open data program becomes re-identified and harms an individual, public trust in the city and in open data is seriously eroded. Citizens may stop providing data, or provide false data, if they believe that it might be exposed in the future. If the data were subject to regulatory or confidentiality provisions, moreover, such disclosures could lead to new compliance costs or lawsuits. For example, in 2012, Philadelphia’s Department of Licenses & Inspections published gun permit appeals as part of its open data initiative. These permits included a free text field where applicants explained why they needed the permit. Some individuals wrote they carried large sums of cash at night. As a consequence of disclosing this information, the City was ultimately charged $1.4 million as part of a class-action lawsuit. One of the lawyers behind the suit stated that the information released was a “road map for criminals.”
Re-identification can cause harms to individuals, to organizations and government agencies, and to society as a whole. Even false claims of re-identification can cause significant damage, leaving individuals uncertain whether their information is exposed and susceptible to lost opportunities or mistaken decisions based on data wrongly attributed to them. Fortunately, however, technologies and controls to mitigate re-identification risk are constantly evolving, and are increasingly available to state and local governments.
Data Quality and Equity
Multiple stakeholders rely on the accuracy of information in public datasets: citizens, companies, community organizations, and other governmental entities. In some circumstances, inaccurate, incomplete, or biased open data may have little impact – for example, a list of sold city fleet vehicles may accidentally record the wrong make and model for a vehicle or two. In other circumstances, however, the consequences can be more lasting, leading to poor or inefficient decision-making, unethical or illegal data uses, or discriminatory outcomes. Publishing the wrong person’s information to an open dataset of DUI arrests, for example, could adversely affect that person’s employment, credit, and insurance prospects for years to come. Because open data is used so widely and for so many diverse purposes, it is critical that any data released be accurate and unbiased.
Personal data that has been made public without legal conditions may be consumed and repurposed by any number of potential actors, including identity thieves, commercial information resellers (and ultimately their clients, including potential employers, insurers, creditors, and others), companies, friends and family, nosy neighbors, stalkers, law enforcement and other government entities, and others. Some commercial “mugshot” or arrest record databases, for example, profit by gathering sensitive personal information via public records, publishing the data to private sites, and then charging individuals a fee to have them removed. The lack of control over downstream uses of open data is a significant point of concern among a variety of open data stakeholders, including civic hackers, legal advocates, and industry representatives.
Over the last few years, organizations increasingly rely on data to automate their decision-making in a wide variety of situations, including everything from traffic management to personalized advertising to insurance rate setting. But particularly in “smart” systems that use algorithmic decision-making and machine learning, bad data can lead to bad policies. For example, both predictive policing and criminal sentencing have repeatedly demonstrated racial bias in both the inputs (historic arrest and recidivism data) and their outputs, leading to new forms of institutional racial profiling and discrimination. Even high quality data, if used out of context or with particular intent, can cause harm and lead to adverse inferences or impacts on individuals and groups.
In fact, even individuals who are not directly represented in an open dataset may nevertheless be impacted by inaccuracies and biases in the dataset or analysis performed on it. For example, according to the City of Seattle, “residents of zip codes listed as having high rates of households below the poverty level; property owners in neighborhoods where crime rates are higher than average; [and] students at schools that are underperforming” may all be adversely effected by conclusions drawn from such datasets, especially if drawn from low-quality data. These sorts of inferential disclosures may result in group harms that have not been traditionally viewed as privacy concerns, and may thus not be well addressed by existing municipal privacy policies and practices.
Moreover, an unfair distribution of data benefits and data risks across a community may reinforce societal biases, disguise prejudiced decision-making, and block equal opportunities for marginalized or vulnerable populations. Some open data stakeholders have raised concerns that, particularly when commercialized, public municipal data may be used to “lower property values, redline insurance, et cetera, in neighborhoods with high crime rates rather than addressing those issues.”
If data represented on the open data program is disproportionately collected from certain populations over others, or is used against certain populations over others, or if the data exposes vulnerable populations to higher privacy risks or at a higher rate than others, it may be inequitable. For example, given that minority and vulnerable populations, including immigrant communities, tend to be over-surveilled in comparison to majority populations, particularly in the context of law enforcement and social services, they may be disproportionately represented in open datasets, creating fertile grounds for inaccuracies and biases in decision making or even just reporting of data. On the other hand, minority or vulnerable populations may also be under-represented in certain datasets, meaning that policy improvements or interventions do not take their needs and circumstances into account. For example, minority populations tend to be underrepresented in 311 datasets, which can skew the distribution of public services to those groups.
Governments must constantly strive to serve all their citizens fairly and equitably, however difficult it may be to strike the balance of equities.
Public Impact
Open data programs cannot succeed in their social, economic, and democratic missions without public trust. Where individuals feel their privacy is violated by a particular dataset being published or that public expectations of privacy were disregarded, they will hold the open data program accountable. This can result not only in a loss of trust in the open data program, but also in undermining the entire city government’s ability to act as a responsible data steward. Civic engagement and communication, paired with demonstrable responsible data practices, can earn the public’s trust in open data. But if the public’s trust in a government as a responsible data steward is damaged, individuals may become unwilling to support and participate in important civic activities and research. It can also lead to the public providing false data in certain circumstances out of a fear their real information would be compromised.
Just as in the event of a data breach, individuals who believe that their personal data may have been exposed to the world will feel uncertainty and anxiety about the loss of informational control and potential long-term ramifications such as identity theft. When personally identifiable information is published to an open data program or a re-identification attack appears successful, individuals often have little recourse. Municipal leaders must be aware that deciding what data they may release about individuals is inextricable from what data they collect about individuals. Failing to address privacy throughout the entire data lifecycle, from collection to use to sharing to deletion, will impede public trust in data-driven municipal programs. For example, cities should be cautious about collecting information that would harm individuals if it were one day shared via the open data program, disclosed via a public records request, or exposed via a data breach.
Finally, cities must be aware that how data is collected and used is as important as how it is released for ensuring public trust in open data programs. Data that is collected directly from individuals by a municipality, with clear notice and consent, will raise fewer privacy concerns than, for example, data that is initially collected by a commercial service and then provided to a municipal regulator. Individuals’ expectations of privacy are highly context-dependent, and the more attenuated the connection between the original purpose for the collection of their personal data and its release through an open data program, the likelier it is that individuals will feel confused or misled by the whole enterprise.
Cities must communicate clearly with individuals about how and when their data can find its way to an open data portal. Vague privacy notices and a lack of an opportunity to opt in or out of data collection may shock or surprise some people, even if that information is in pseudonymized or aggregate form. And if data is used for a purpose other than the reason the collection occurred without citizens’ consent to repurpose, significant privacy concerns are raised, as well as ethical and technical questions. It is possible that an individual never would have consented to the data collection if they it would ultimately be released through the open data program. Where an individual’s privacy – or trust – has been violated by a government data program once, it may be impossible to restore.
The transparency goals of municipal open data programs are critical to the improvement of civic life and institutions in the modern city, and rely on the release of microdata about the city and its citizens’ activities. And yet people who provide personal information to their governments must be able to trust that their privacy will be protected. If individuals find their personal information exposed, or their neighborhoods singled out or discriminated against, or their data collected for one purpose and used for another, this can undermine public trust in the city as a whole and slow or even reverse the momentum of the open data program. On the other hand, where cities engage the public and communicate the benefits of the open data program while clearly addressing any shortcomings, they may build public trust. Responsible privacy practices and effective communication provide the foundation for successful, trustworthy, and innovative open data programs.
Model Open Data Benefit Risk Analysis
In the open data context, considering only the risks of the dataset is merely one part of a balanced value equation; decision-makers must also take count of the project’s benefits in order to make a final determination about whether to proceed with publishing the dataset openly. For the purposes of this draft report, FPF developed a Model Open Data Benefit Risk Analysis based on risk assessment and de-identification frameworks developed by the National Institute of Standards and Technology and also builds on parallel efforts by researchers at the University of Washington, the Berkman Klein Center, the City of San Francisco, and the U.S. Census Bureau to develop robust risk-based frameworks for government data releases. This template provides a structure for vetting potential open datasets in five steps:
Step 1: Evaluate the Information Contained in the Dataset. This step includes identifying whether there are direct or indirect identifiers, sensitive attributes, or information that is difficult to de-identify present in the dataset; assessing how linkable the information might be to other datasets; and considering the context in which the data was obtained.
Step 2: Evaluate the Benefits Associated with Releasing the Dataset. This step considers the potential benefits and users of the dataset, and assesses the magnitude of the potential benefits against the likelihood of their occurring.
Step 3: Evaluate the Risks Associated with Releasing the Dataset. This step considers the potential privacy risks and negative users of the dataset, and assesses the magnitude of the potential risks against the likelihood of their occurring.
Step 4: Weigh the Benefits against the Risks of Releasing the Dataset. This step combines the overall scores from steps 2 and 3 to determine an appropriate method for releasing (or not releasing) the dataset. Recommendations include releasing as open data, in a limited access environment, or not publishing at the current time. This section also overviews common methods for reducing re-identification risk in terms of their privacy-protective, utility, and operational impacts.
Step 5: Evaluate Countervailing Factors. This step provides a final opportunity to document any countervailing factors that might justify releasing a dataset openly regardless of its privacy risk, such as when there is a compelling public interest in the information.
See Appendix B for the full template.
The City of Seattle as a Model Municipality
Given the risks described above, FPF conducted the following assessment to evaluate the City of Seattle as a model municipality based on its organizational structure and data handling practices related to open data. The assessment is grounded in public documentation and interviews with privacy, open data, and disclosure control experts and with Seattle IT and Open Data Leadership, departmental Open Data and Privacy Champions, and local community advisors.
Our scoring of the City of Seattle’s practices in each of the following domains is based on the AICPA/CICA Privacy Maturity Model (PMM) levels, which reflect Generally Accepted Privacy Principles (GAPP):
- Ad hoc – procedures or processes are generally informal, incomplete, and inconsistently applied.
- Repeatable – procedures or processes exist; however, they are not fully documented and do not cover all relevant aspects.
- Defined – procedures and processes are fully documented and implemented, and cover all relevant aspects.
- Managed – reviews are conducted to assess the effectiveness of the controls in place.
- Optimized – regular review and feedback are used to ensure continuous improvement towards optimization of the given process.
A key principle of the PMM approach is the recognition that “each organization’s personal information privacy practices may be at various levels, whether due to legislative requirements, corporate policies or the status of the organization’s privacy initiatives. It was also recognized that based on an organization’s approach to risk, not all privacy initiatives would need to reach the highest level on the maturity model.”
Privacy leadership and program management
- Does the municipality employ a comprehensive, strategic, agency-wide privacy program regarding its open data initiatives?
- Has the municipality designated a privacy governance leader for Open Data?
- Is the Open Data program guided by core privacy principles and policies?
- Does the open data workforce receive effective privacy training and education?
- Are the municipality’s open data privacy policies and procedures updated in light of ongoing monitoring and periodic assessments?
Benefit-risk assessment
- Does the Open Data program conduct a benefit-risk assessment to manage privacy risk in each dataset considered for publication?
- Are datasets assessed based on the identifiability, sensitivity, and utility of the data prior to release?
- Are inventories of published personally identifiable information maintained?
- Are benefit-risk assessments documented and regularly reviewed?
- Does the Open Data program have a mechanism in place to trigger re-assessment of a published dataset in light of new facts?
De-identification tools and strategies
- Does the Open Data program utilize technical, legal, and administrative safeguards to reduce re-identification risk?
- Does the Open Data program have access to disclosure control experts to evaluate re-identification risk?
- Does the Open Data program have access to appropriate tools to de-identify unstructured or dynamic data types? (e.g., geographic, video, audio, free text, real time sensor data).
- Does the Open Data program have policies and procedures for evaluating re-identification risk across databases? (e.g., risk created by intersection of multiple municipal databases, King County open data, Washington State open data, federal open data, commercial databases).
- Does the Open Data program evaluate privacy risk in light of relevant public records laws?
Data quality
- Does the municipality employ reasonable policies and procedures for the open data program to ensure that personally identifiable information is accurate, complete, and current?
- Does the Open Data program check for, and correct as appropriate, inaccurate, or outdated personally identifiable information?
- Are there procedures or mechanisms for individuals to submit correction requests for potentially incorrect personally identifiable information posted on the open data program?
Equity and fairness
- Were the conditions under which the data was collected fair? (e.g., were citizens aware that the data would be published on the open data portal? If data was acquired from a third party, were terms and conditions observed in the collection, use, maintenance, and sharing of the data?).
- Does the Open Data program assess the representativeness of the open data portal? (e.g. whether underserved or vulnerable populations are appropriately represented in the data, or whether underserved or vulnerable populations’ interests are taken into account when determining what data to publish).
- Are any procedures and mechanisms in place for people to submit complaints about the use of data or about the open data process generally, as well as procedures for responding to those complaints?
Transparency and public engagement
- Does the Open Data program engage and educate the public about the benefits of open data?
- Does the Open Data program engage and educate the public about the privacy risks of open data?
- Does the Open Data program provide opportunities for public input and feedback about the program, the data available, and privacy, utility, or other concerns?
- Does the Open Data program engage with the public when developing of open data privacy protections?
- Does the Open Data program consider the public interest in determining what datasets to publish?
- Does the Open Data program communicate with the public about why some datasets may include personally identifiable information?
Model Open Data Risk Analysis applied to the current Seattle Open Data content
FPF will review a subset of content available on the open data program from high-risk agencies, as well as a random sample of additional agencies or datasets, and apply the final model template to evaluate their potential privacy risk relative to their potential benefits to the public. The datasets contemplated to be included in the Final Report are:
- Real Time Fire 911 Calls
- Building Permits (Current)
- Sold Fleet Equipment
- Seattle Communities Online Inventory
- Road Weather Information Stations
Recommendations and Conclusion
As the City of Seattle Open Data program evolves and matures, it must continue developing the specialized resources and tools to address the privacy risks inherent in open data. The Seattle Open Data program will be building on a strong foundation, but there are always steps that can be taken to improve the depth and breadth of municipal privacy protections. The final report will detail concrete technical, operational, and organizational recommendations to elevate the Seattle Open Data program’s approach to identifying and addressing privacy risks.
The City of Seattle is one of the most innovative cities in the country, with engaged and civic-minded citizenry, active city leadership, and technologically sophisticated business community. By continuing to complement its growing open data program with robust privacy protections and policies, it will be possible for the City of Seattle to live up to the promise of its Open Data Policy, supporting civic innovation while protecting individual privacy.
Appendix A: Additional Resources
AICPA/CICA PRIVACY TASK FORCE, AICPA/CICA PRIVACY MATURITY MODEL, (2011), https://www.kscpa.org/writable/files/AICPADocuments/10-229_aicpa_cica_privacy_maturity_model_finalebook.pdf.
Micah Altman et al., Towards a Modern Approach to Privacy-Aware Government Data Releases, 30 BERKELEY TECH. L.J. 1968 (2015), https://cyber.harvard.edu/publications/2016/Privacy_Aware_Government_Data_Releases.
SEAN BROOKS ET AL., AN INTRODUCTION TO PRIVACY ENGINEERING AND RISK MANAGEMENT IN FEDERAL SYSTEMS NISTIR 8062 (NIST Jan. 2017), http://nvlpubs.nist.gov/nistpubs/ir/2017/NIST.IR.8062.pdf.
JOSEPH A. CANNATACI, REPORT OF THE SPECIAL RAPPORTEUR ON THE RIGHT TO PRIVACY (Appendix on Privacy, Big Data, and Open Data) (Human Rights Council, Mar. 8, 2016), www.ohchr.org/Documents/Issues/Privacy/A-HRC-31-64.doc.
Lorrie Cranor, Open Police Data Re-identification Risks, TECH@FTC BLOG (April 27, 2016, 3:31 PM), https://www.ftc.gov/news-events/blogs/techftc/2016/04/ open-police-data-re-identification-risks.
David Doyle, Open Government Data: an analysis of the potential impacts of an Open Data law for Washington State (2015) (unpublished M.P.P. thesis, University of Washington Bothell), https://digital.lib.washington.edu/researchworks/bitstream/handle/1773/34826/Doyle%20-%20Capstone.pdf?sequence=1.
MARK ELLIOT, ELAINE MACKEY, KIERON O’HARA & CAROLINE TUDOR, THE ANONYMISATION DECISION-MAKING FRAMEWORK (2016), http://ukanon.net/wp-content/uploads/2015/05/The-Anonymisation-Decision-making-Framework.pdf.
Khaled El Emam, A de-identification protocol for open data, IAPP (May 16, 2016), https://iapp.org/news/a/a-de-identification-protocol-for-open-data/.
KHALED EL EMAM, GUIDE TO THE DE-IDENTIFICATION OF PERSONAL HEALTH INFORMATION (CRC Press, 2013).
KHALED EL EMAM & WAËL HASSAN, A PRIVACY ANALYTICS WHITE PAPER: THE DE-IDENTIFICATION MATURITY MODEL (PrivacyAnalytics, 2013).
Federal Committee on Statistical Methodology, Report on Statistical Disclosure Limitation Methodology, Statistical Policy Working Paper No. 22 (2005), https://www.hhs.gov/sites/default/files/spwp22.pdf.
Kelsey Finch & Omer Tene, Welcome to the Metropticon: Protecting Privacy in a Hyperconnected Town, 41 FORDHAM URB. L.J. 1581 (2015), http://ir.lawnet.fordham.edu/cgi/viewcontent.cgi?article=2549&context=ulj.
Kelsey Finch & Omer Tene, The City as a Platform: Enhancing Privacy and Transparency in Smart Communities, CAMBRIDGE HANDBOOK OF CONSUMER PRIVACY (forthcoming 2018).
ERICA FINKEL, DATASF: OPEN DATA RELEASE TOOLKIT (2016), https://drive.google.com/file/d/0B0jc1tmJAlTcR0RMV01PM2NyNDA/view.
SIMSON L. GARFINKEL, SP 800-188: DE-IDENTIFYING GOVERNMENT DATASETS (NIST draft. Aug. 2016), http://csrc.nist.gov/publications/drafts/800-188/sp800_188_draft2.pdf.
SIMSON L. GARFINKEL, NISTIR 8053: DE-IDENTIFYING PERSONAL INFORMATION (NIST Oct. 2015), http://nvlpubs.nist.gov/nistpubs/ir/2015/NIST.IR.8053.pdf.
Ben Green et al., Open Data Privacy, BERKMAN KLEIN CENTER FOR INTERNET & SOCIETY AT HARVARD (2017), https://dash.harvard.edu/bitstream/handle/1/30340010/OpenDataPrivacy.pdf.
Emily Hamilton, The Benefits and Risks of Policymakers’ Use of Smart City Technology (Oct. 2016), https://www.mercatus.org/system/files/mercatus-hamilton-smart-city-tools-v1.pdf.
INFORMATION COMMISSIONER’S OFFICE, ANONYMISATION: MANAGING DATA PROTECTION RISK CODE OF PRACTICE (2012), https://ico.org.uk/media/1061/anonymisation-code.pdf.
ISO/IEC CD 20889: Information technology – Security techniques – Privacy enhancing data de-identification techniques, https://www.iso.org/standard/69373.html?browse=tc.
ANNA JOHNSTON, DEMYSTIFYING DE-IDENTIFICATION: AN INTRODUCTORY GUIDE FOR PRIVACY OFFICERS, LAWYERS, RISK MANAGERS AND ANYONE ELSE WHO FEELS A BIT BEWILDERED (Salinger Privacy, Feb. 2017).
JOINT TASK FORCE TRANSFORMATION INITIATIVE INTERAGENCY WORKING GROUP, GUIDE FOR CONDUCTING RISK ASSESSMENTS NIST 800-30 (NIST Sep. 2012), http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-30r1.pdf .
Jeff Jonas & Jim Harper, Open Government: The Privacy Imperative, in OPEN GOVERNMENT: COLLABORATION, TRANSPARENCY, AND PARTICIPATION IN PRACTICE (O’Reilly Media, 2010).
ROB KITCHIN, THE DATA REVOLUTION: BIG DATA, OPEN DATA, DATA INFRASTRUCTURES AND THEIR CONSEQUENCES (Sage, 1st ed. 2014).
YVES-ALEXANDRE DE MONTJOYE ET AL., UNIQUE IN THE CROWD: THE PRIVACY BOUNDS OF HUMAN MOBILITY (Scientific Reports 3, Mar. 25, 2013), https://www.nature.com/articles/srep01376.
Sean A. Munson et al., Attitudes toward Online Availability of US Public Records, DG.O 11 (2011), HTTP://WWW.VSDESIGN.ORG/PUBLICATIONS/PDF/PUBLICDATA_DGO_V11_1.PDF.
Arvind Narayanan et al., A Precautionary Approach to Big Data Privacy, in 24 DATA PROTECTION ON THE MOVE: LAW, GOVERNANCE AND TECHNOLOGY SERIES (Serge Gutwirth, Ronald Leenes, Paul de Hert eds., 2016).
Opinion of the Article 29 Data Protection Working Party on Anonymisation Techniques (Apr. 2014), https://cnpd.public.lu/fr/publications/groupe-art29/wp216_en.pdf.
Jules Polonetsky, Omer Tene & Kelsey Finch, Shades of Gray: Seeing the Full Spectrum of Practical Data De-Identification, 56 SANTA CLARA L. REV. 594 (2016), http://digitalcommons.law.scu.edu/cgi/viewcontent.cgi?article=2827&context=lawreview.
JULES POLONETSKY, OMER TENE & JOSEPH JEROME, BENEFIT-RISK ANALYSIS FOR BIG DATA PROJECTS (Sept. 2014), https://fpf.org/wp-content/uploads/FPF_DataBenefitAnalysis_FINAL.pdf.
PRESIDENT’S COUNCIL OF ADVISORS ON SCIENCE AND TECHNOLOGY, EXEC. OFFICE OF THE PRESIDENT, Report to the President: Technology and the Future of Cities (Feb. 2016), https://www.whitehouse.gov/sites/whitehouse.gov/files/images/Blog/PCAST%20Cities%20Report%20_%20FINAL.pdf.
Ira Rubinstein & Woodrow Hartzog, Anonymization and Risk, 91 WASH. L REV. 703 (2016), http://digital.law.washington.edu/dspace-law/bitstream/handle/1773.1/1589/91WLR0703.pdf?sequence=1&isAllowed=y.
Sander v. State Bar of California, 58 Cal. 4th 300 (2013).
Checklist on Disclosure Potential of Data, U.S. CENSUS BUREAU (Feb. 20, 2013), https://www.census.gov/srd/sdc/drbchecklist51313.docx.
Jan Whittington et al., Push, Pull, and Spill: A Transdisciplinary Case Study in Municipal Open Government, 30 BERKELEY TECH. L.J. 1899 (2015), http://btlj.org/data/articles2015/vol30/30_3/1899-1966%20Whittington.pdf.
Alexandra Wood et al., Privacy and Open Data Research Briefing, BERKMAN KLEIN CENTER FOR INTERNET & SOCIETY AT HARVARD (2016), https://dash.harvard.edu/bitstream/handle/1/28552574/04OpenData.pdf?sequence=1.
Frederik Zuiderveen Borgesius et al., Open Data, Privacy, and Fair Information Principles: Towards a Balancing Framework, 30 BERKELEY TECH. L.J. 2075 (2015), http://btlj.org/data/articles2015/vol30/30_3/2073-2132%20Borgesius.pdf.
Seattle Resources
CITY OF SEATTLE, CITY OF SEATTLE 2017 OPEN DATA PLAN, http://www.seattle.gov/Documents/Departments/SeattleIT/City%20of%20Seattle%202017%20Open%20Data%20Plan.pdf.
CITY OF SEATTLE, OPEN DATA PLAYBOOK V. 1.0, http://www.seattle.gov/Documents/Departments/SeattleGovPortals/CityServices/OpenDataPlaybook_Published_2016.08.pdf.
CITY OF SEATTLE, OPEN DATA POLICY, http://www.seattle.gov/Documents/Departments/SeattleGovPortals/CityServices/OpenDataPolicyV1.pdf
CITY OF SEATTLE, OPEN DATA PROGRAM 2016 ANNUAL REPORT, https://www.seattle.gov/Documents/Departments/SeattleIT/Open%20Data%20Program%202016%20Annual%20Report.pdf.
CITY OF SEATTLE, PRIVACY PRINCIPLES, https://www.seattle.gov/Documents/Departments/InformationTechnology/City-of-Seattle-Privacy-Principles-FINAL.pdf.
Seattle Information Technology: Community Technology Advisory Board (CTAB), SEATTLE.GOV, https://www.seattle.gov/tech/opportunities/ctab.
Seattle Information Technology: Privacy, SEATTLE.GOV, http://www.seattle.gov/tech/initiatives/privacy.
Seattle Information Technology: Open Dataset Inventory – Privacy and PII, SEATTLE.GOV, https://view.officeapps.live.com/op/view.aspx?src=http://www.seattle.gov/Documents/Departments/SeattleIT/OpenDatasetInventory_Privacy_PII.docx.
Appendix B: Model Open Data Benefit Risk Analysis
Dataset Title: .................................................................................................................................
Step 1: Evaluate the Information the Dataset Contains
Consider the following categories of information:
-
Direct Identifiers: These are data points that identify a person without additional information or by linking to information in the public domain. “Personally Identifiable Information,” or PII, often falls within this category. For example, they can be names, social security numbers, or an employee ID number. See PII/Privacy in the Open Dataset Inventory guidance. Publishing direct identifiers creates a very high risk to privacy because they directly identify an individual and can be used to link other information to that individual.
-
Indirect Identifiers: These are data points that do not directly identify a person, but that in combination can single out an individual. This could include information such as birth dates, ZIP codes, gender, race, or ethnicity. In general, to preserve privacy, experts recommend including no more than 6-8 indirect identifiers in a single dataset. If a dataset includes 9 or more indirect identifiers there is a high or very high risk to privacy because they can indirectly identify an individual.
-
Non-Identifiable Information: This is information that cannot reasonably identify an individual, even in combination. For example, this might include city vehicle inventory, GIS data, or atmospheric readings. This data creates very low or low risk to privacy.
-
Sensitive Attributes: These data points that may be sensitive in nature. Direct and indirect identifiers can be sensitive or not, depending on context. For example, this might include financial information, health conditions, or a criminal justice records. Sensitive attributes typically create moderate, high, or very high risk to privacy.
-
Spatial Data and Other Information that Is Difficult to De-identify: Certain categories or data are particularly difficult to remove identifying or identifiable information from, including: geographic locations, unstructured text or free-form fields, biometric information, and photographs or videos. If direct or indirect identifiers are in one of these data formats, they may create a moderate, high, or very high risk to privacy.
Consider how linkable the direct and indirect identifiers in this dataset are to other datasets:
-
Do any of the dataset’s direct or indirect identifiers currently appear in other readily accessible open datasets, such as Data.Seattle.gov, Data.KingCounty.gov, or Data.WA.gov? If this information is present in multiple open datasets, it increases the chances of identifying an individual and increases the risk to privacy.
-
How often is the dataset updated? In general, the more frequently a dataset is updated—every fifteen minutes versus every quarter, for example—the easier it is to re-identify an individual and the greater the risk to privacy.
-
How often is the information in this dataset requested by public records? (If the underlying data have been made available through public records requests, de-identification or other mitigations may be less effective).
Consider how the direct and indirect identifiers in this dataset were obtained:
-
In what context was this data collected: Is this data collected under a regulatory regime? (If the release of the data is legally regulated, they create a high or very high risk to privacy). Are there any conditions, such as a privacy policy or contractual term, attached to the data? If the personal information in this dataset collected directly from the individual or from a third party?
-
Would there be a reasonable expectation of privacy in the context of the data collection? For example, if the public has no notice of the data collection or data are collected from private spaces, there may be an expectation of privacy.
-
Was the collection of the information in this dataset controversial?
-
Was any of the information in this dataset collected by surveillance technologies (e.g., bodyworn cameras, surveillance cameras, unmanned aerial vehicles, automatic license plate readers, etc.)?
-
Has the personal information in this dataset been checked for accuracy? Is there a mechanism for individuals to have information about themselves in this dataset corrected or deleted?
-
Is there a concern that releasing this data may lead to public backlash or negative perceptions?
Step 2: Evaluate the Benefits Associated with Releasing the Dataset
List some of the foreseeable benefits of publishing the data fields included in this dataset. For example, measuring atmospheric data at particular locations over time may reveal useful weather patterns, and tracking building permit applications may reveal emerging demographic or commercial trends in particular neighborhoods.
Consider the likely users of this dataset. Who are the ideal users?
- Individuals
- Community Groups
- Journalists
- Researchers
- Companies or Private Entities
- Other Government Agencies or Groups
- Other: .......................................................................
Assess the scope of the foreseeable benefits of publishing the dataset on a scale of 1-10:
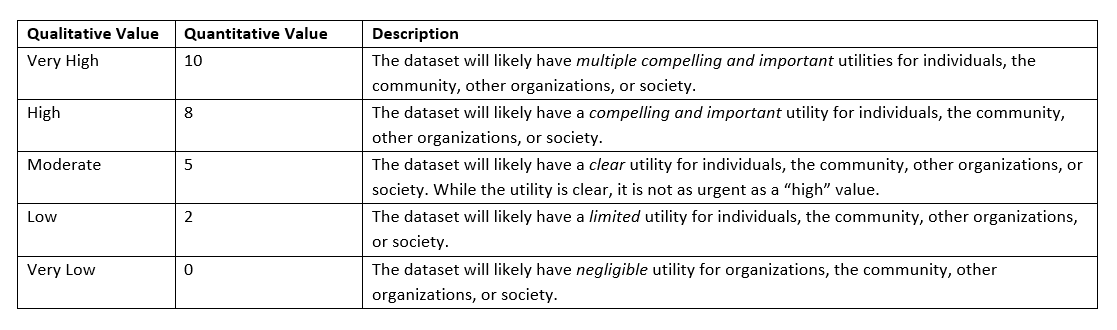
Next, assess the likelihood that the desired benefits of releasing this dataset would occur:

Combining your rating of the foreseeable benefits of the dataset with the likelihood that these benefits will occur, assess the overall benefit of this dataset:

Step 3: Evaluate the Risks Associated with Releasing the Dataset
Consider the foreseeable privacy risks of this dataset:
Re-identification (and false re-identification) impacts on individuals:
- Would a re-identification attack on this dataset expose the person to identity theft, discrimination, or abuse?
- Would a re-identification attack on this dataset reveal location information that could lend itself to burglary, property crime, or assault?
- Would a re-identification attack on this dataset expose the person to financial harms or loss of economic opportunity?
- Would a re-identification attack on this dataset reveal non-public information that could lead to embarrassment or psychological harm?
Re-identification (and false re-identification) impacts on the organization:
- Would a re-identification attack on this dataset lead to embarrassment or reputational damage to the City of Seattle?
- Would a re-identification attack on this dataset harm city operations relying on maintaining data confidentiality?
- Would a re-identification attack on this dataset expose the city to financial impact from lawsuits, or civil or criminal sanctions?
- Would a re-identification attack on this dataset undermine public trust in the government, leading to individuals refusing to consent to data collection or providing false data in the future?
Data quality and equity impacts:
- Will inaccurate or incomplete information in this dataset create or reinforce biases towards or against particular groups?
- Does this dataset contain any incomplete or inaccurate data that, if relied upon, would foreseeably result in adverse or discriminatory impacts on individuals?
- Will any group or community’s data be disproportionately included in or excluded from this dataset?
- If this dataset is de-identified through statistical disclosure measures, did that process introduce significant inaccuracies or biases into the dataset?
Public impacts:
- Does this dataset have information that would lead to public backlash if made public?
- Will local individuals or communities be shocked or surprised by the information about themselves in this dataset?
- Is it likely that the information in this dataset will lead to a chilling effect on individual, commercial, or community activities?
- Is there any information contained within the dataset that would, if made public, reveal nonpublic information about an agency’s operations?
Consider who could use this information improperly or in an unintended manner (including to re-identify individuals in the dataset):
- General public (individuals who might combine this data with other public information)
- Re-identification expert (a computer scientist skilled in de-identification)
- Insiders (a City employee or contractor with background information about the dataset)
- Information brokers (an organization that systematically collects and combines identified and de-identified information, often for sale or reuse internally)
- “Nosy neighbors” (someone with personal knowledge of an individual in the dataset who can identify that individual based on the prior knowledge)
- Other: .......................................................................
Assess the scope of the foreseeable privacy risks of publishing the dataset on a scale of 1-10:
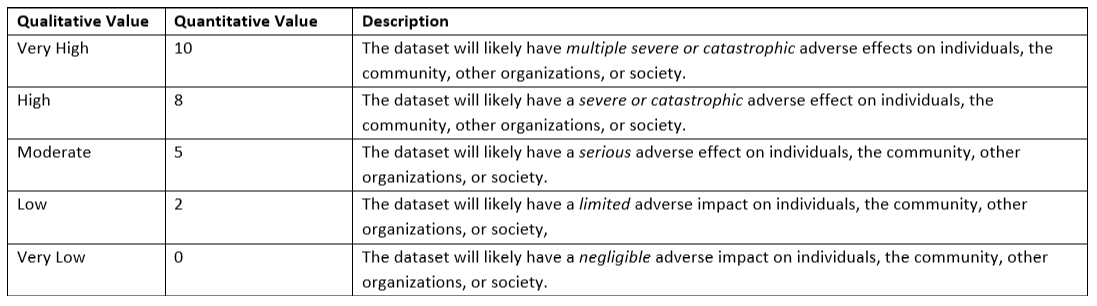
Next, assess the likelihood that the desired risks of releasing this dataset would occur:

Combining your rating of the foreseeable risks of the dataset with the likelihood that these risks will occur, assess the overall risk of this dataset:
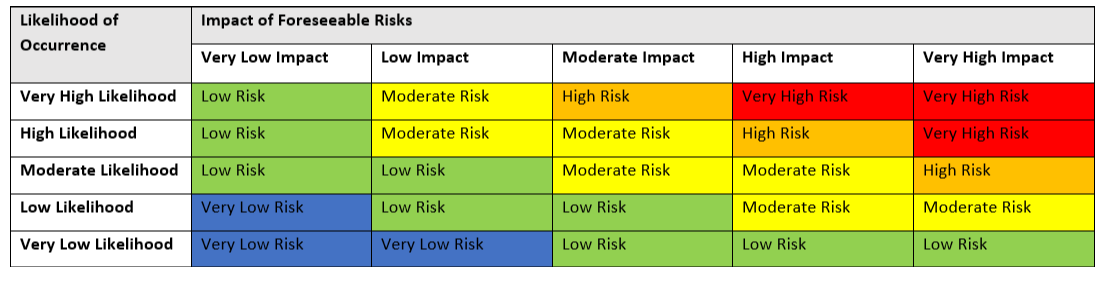
Step 4: Weigh the Benefits against the Risks of Releasing the Dataset
Step 4A: Combine the overall scores from the benefit and risk analyses to determine the appropriate solution for how to treat the dataset.
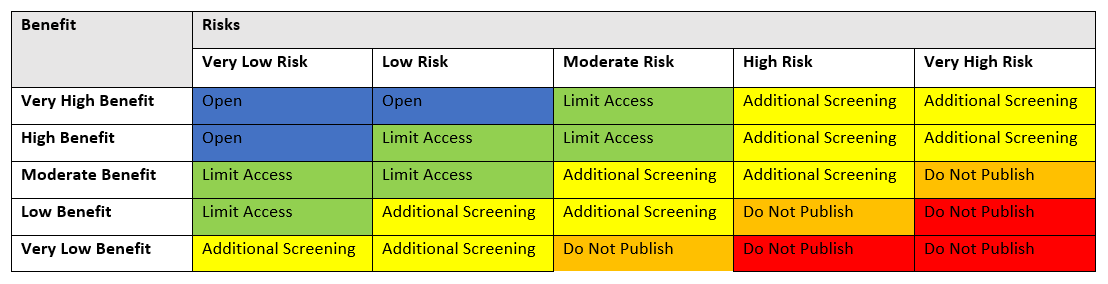
- Open: Releasing this dataset to the public presents low or very low privacy risk to individuals, or the potential benefits of the dataset substantially outweigh the potential privacy risks. If the combination of risks and benefits resulted in an “Open” selection in the light green band, consider mitigating the data to further lower the risk.
- Limit Access: Releasing this data would create a moderate privacy risk, or the potential benefits of the dataset do not outweigh the potential privacy risks. In order to protect the privacy of individuals, limit access to the dataset such as by attaching contractual/Terms of Service terms to the data prohibiting re-identification attempts.
- Additional Screening: Releasing this dataset would create significant privacy risks and the potential benefits do not outweigh the potential privacy risks. In order to protect the privacy of individuals, formal application and oversight mechanisms should be considered (e.g., an institutional review board, data use agreements, or a secure data enclave).
- Do Not Publish: Releasing this dataset poses a high or very high risk to individual’s privacy or the potential privacy risks of the dataset significantly outweigh the potential benefits. This dataset should remain closed to the public, unless there are countervailing public policy reasons for publishing it.
If the above table results in an “Open” categorization, then record the final benefit-risk score and prepare to publish the dataset openly.
If the above table does not result in an “Open” categorization, then proceed to Step 4B by applying appropriate de-identification controls to mitigate the privacy risks for this dataset. The de-identification methods described below will be appropriate for some datasets, but not for others. Consider the level of privacy risks you are willing to accept, the overall benefit of the dataset, and the operational resources available to mitigate re-identification risk. Note that the more invasive the de-identification technique, the greater the loss of utility will be in the data, but also the greater the privacy protection will be.
Technical Controls
Special thanks to the Berkman Klein Center for Internet & Society at Harvard University whose work provides a foundation for this analytic framework (See Appendix A).
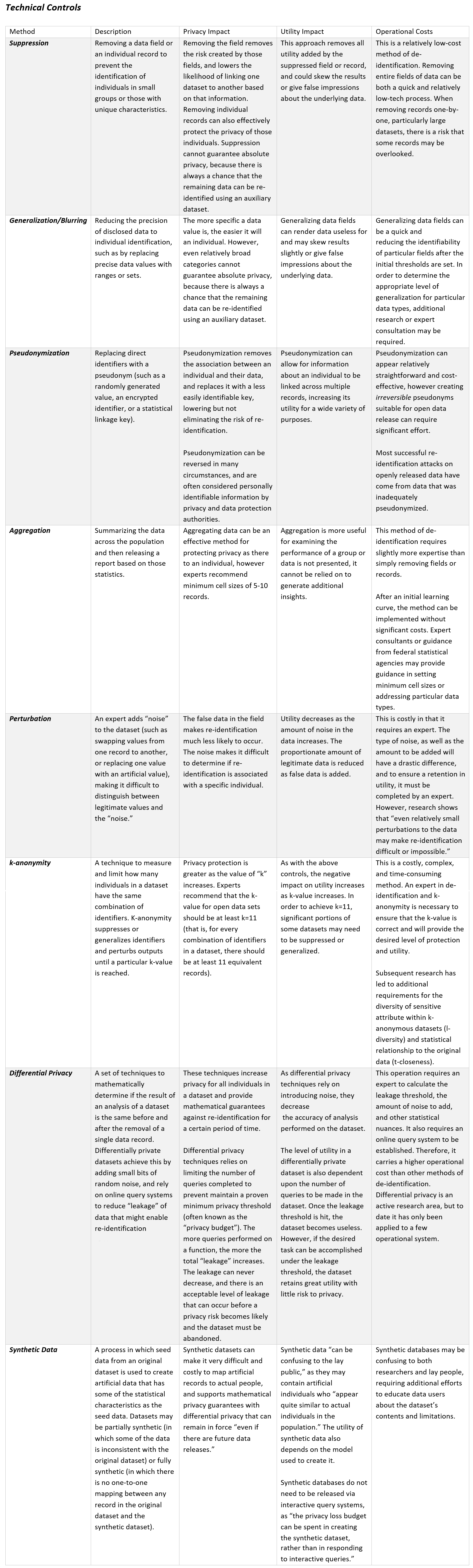
Administrative Controls
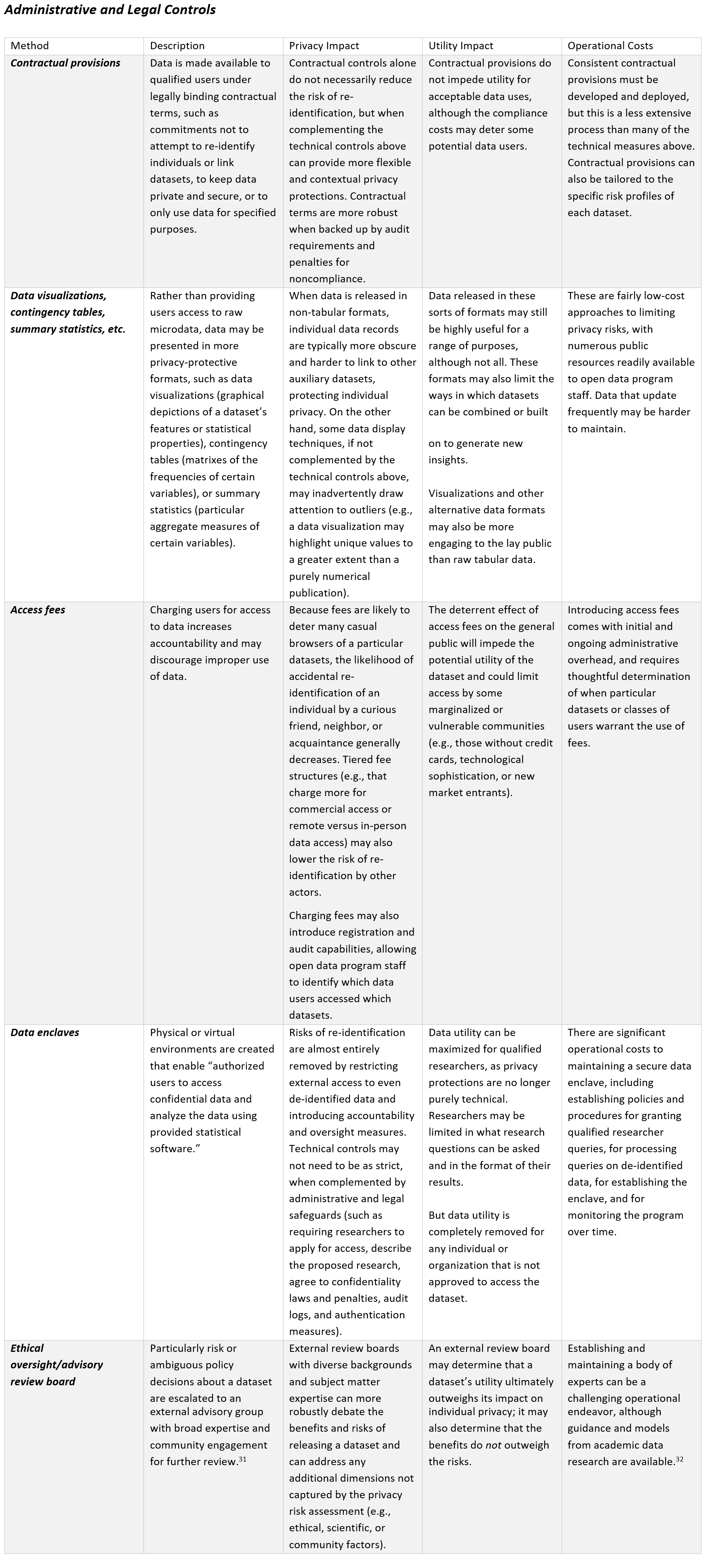
Step 4B: After determining and applying appropriate privacy controls and mitigations for the dataset, re-assess the overall risks and benefits of the dataset (Steps 1-3). Note any mitigation steps taken, and record the final benefit-risk score:
If the score is still not “Open,” consider using another re-identification method. If this is not possible, then determine whether to publish the dataset. If the dataset is categorized as “Additional Screening” or “Do Not Publish” but there may be countervailing public policy factors that should be considered, move on to Step 5.
- Open: Releasing this dataset to the public presents low or very low privacy risk to individuals, or the potential benefits of the dataset substantially outweigh the potential privacy risks. If the combination of risks and benefits resulted in an “Open” selection in the light green band, consider mitigating the data to further lower the risk.
- Limit Access: Releasing this data would create a moderate privacy risk, or the potential benefits of the dataset do not outweigh the potential privacy risks. In order to protect the privacy of individuals, limit access to the dataset such as by attaching contractual/Terms of Service terms to the data prohibiting re-identification attempts.
- Additional Screening: Releasing this dataset would create significant privacy risks and the potential benefits do not outweigh the potential privacy risks. In order to protect the privacy of individuals, formal application and oversight mechanisms should be considered (e.g., an institutional review board, data use agreements, or a secure data enclave).
- Do Not Publish: Releasing this dataset poses a high or very high risk to individual’s privacy or the potential privacy risks of the dataset significantly outweigh the potential benefits. This dataset should remain closed to the public, unless there are countervailing public policy reasons for publishing it.
Step 5: Evaluate Countervailing Factors
Sometimes, a dataset with a very high privacy risk is still worth releasing into the open data program in light of public policy considerations. For example, a dataset containing the names and salaries of elected officials would likely be considered high-risk due to the inclusion of a direct identifier. However, there is a compelling public interest in making this information available to citizens that outweighs the risk to individual privacy.
Additionally, there are always risks associated with maintaining and releasing any kind of data relating to individuals. Two key considerations when deciding whether to release the data irrespective of a potentially high or very high risk to individual privacy are:
- If you are on the edge between two categories, analyze the dataset holistically but err on the side of caution. A dataset that is not released immediately can still be released at another date, as additional risk mitigation techniques become available. A dataset that has been released publicly, however, cannot ever be fully pulled back, even if it is later discovered to pose a greater risk to individual privacy. Be particularly cautious about moving data from an original recommendation of Do Not Publish to Open, and ensure that the potential benefits of releasing the data are truly so likely and compelling that they outweigh the existing privacy risks.
- Any time you deviate from the original analysis, document your reasoning for doing so. This will not only help you decide whether the deviation is, in fact, the correct decision, but also provides accountability. Should the need arise, you will have a record of your reasoning, including analysis of the expected benefits and the recognized risks at the time. Where personally identifiable information is published notwithstanding the privacy risk, accountability mechanisms help maintain trust in the Open Data program that may otherwise be lost.
END
Francesca man
example link
Francesca man
JAMB CAPS Admission
Francesca man
[url=https://www.bentenblog.com/jamb-caps-admission-status/]JAMB CAPS Admission [/url]
Francesca man
https://www.bentenblog.com/jamb-caps-admission-status/
costco employee
costco employee Compensation: The top 15 companies for pay and benefits - USA Today Mar 3, 2018 - Costco currently pays all employees more than $13 an hour, well above ... job and your pay goes up on its own," says one Costco employee.
costco employee
https://www.costcoemployeesite.xyz/
costco employee
https://www.costcoemployeesite.xyz/ [url]https://www.costcoemployeesite.xyz/[/url] costco employee
Dazza Greenwood
This is excellent. If resources and time permit, it would be great to see a slightly shorter/simpler/streamlined version of this in the form of an app (or service) and a generic version of the full document suitable for city-specific customization.
Showing 1 to 4 of 4 entries